ETSS AG
Engineering, technical and scientific services
PERST

Integrative prospective early risk screening tool prototype (PERST)
PERST is a prototype of a prospective early risk screening tool (software and services) developed for the EU-based project NANORIGO. It integrates predictive computations for humans and environments based on questions concerning exposed organisms‘ risk and vulnerability by combining the load contamination of potential pollutants with toxicity and ecotoxicity considerations and data. The source of such potential risks (contamination) is identified as the manufacturing and use of any products and in the emission (exposure) of their materials to humans and nature, particularly product ingredients that should not be emitted during and after the product use.
Thus, PERST aims to predict and target specific product ingredients, including newly engineered nanomaterials and their lifecycle-long location in and migration through environmental (human) and technical systems (Fig. 1). Such product material monitoring also considers its degradation and accumulation in any of the receiving media mentioned above. Material load (exposure) concentrations are computed for the target environments and bioaccumulation bodies listed below. Then, they are compared to toxicological or ecotoxicological concentration data for the target material. From such comparisons, risk is predicted for humans and the environment. The following compartments and organisms (creatures) at risk are considered: air, freshwaters, marine waters, groundwater, saline groundwater, freshwater sediments, marine water sediments, soils, freshwater flora, marine water flora, freshwater fauna, marine water fauna and child and adult humans.
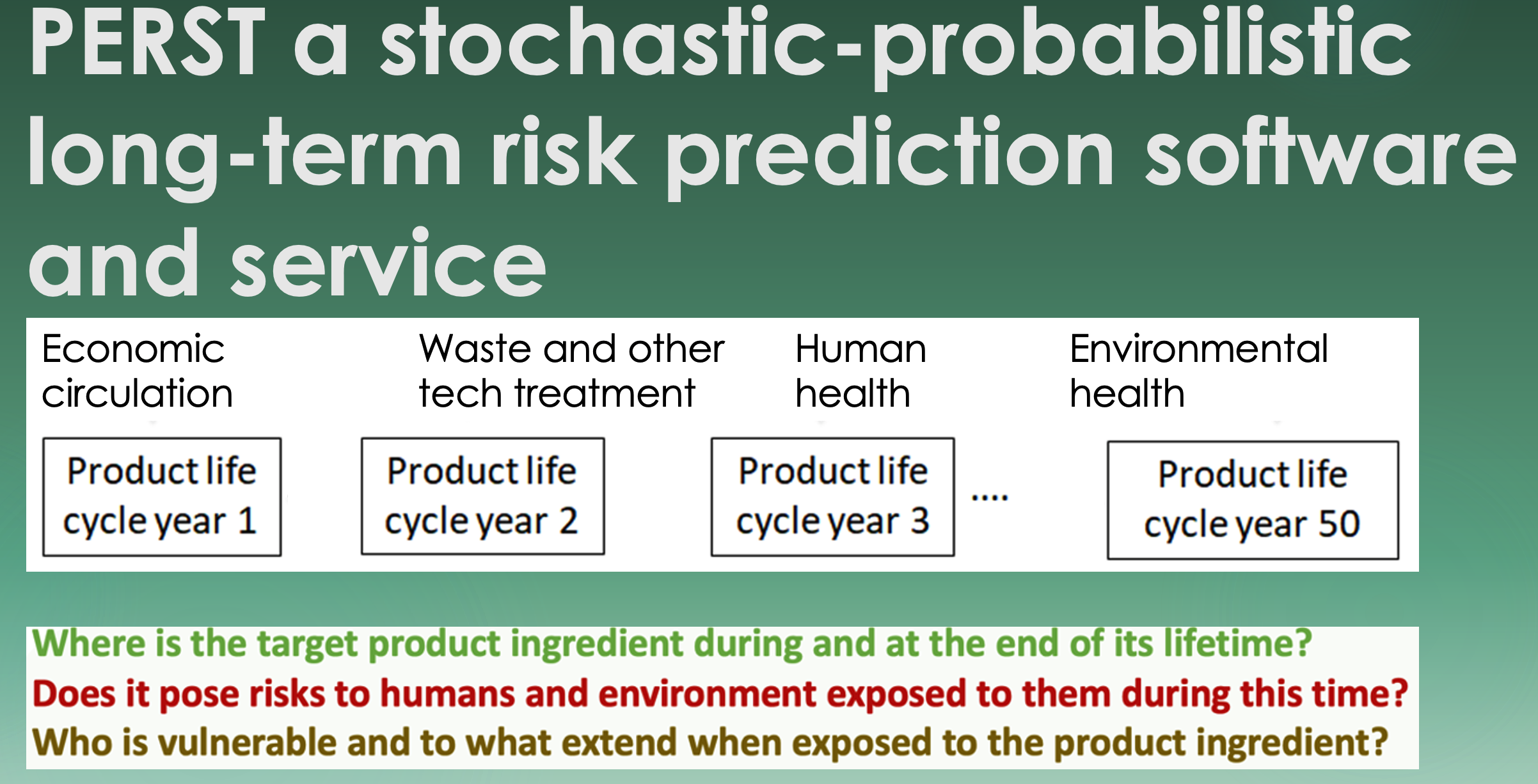
Figure 1: Stochastic probabilistic long-term product material (ingredient) interaction between life phases, media and environments.
PERST’s services may be used in target regions covering all EU member states, Switzerland and the UK. The status quo of available information on a material’s routine use, emission patterns, and – to some extent – fate (residence time) in potentially exposed compartments (bioaccumulation bodies) will be needed in a form that can be linked to tool computations. In doing so, PERST’s services would remain easy to use, as there is no need for the user to deal with probabilistic data and prediction routines, meaning no programming skills are needed. Producers or stakeholders must provide, among others, data on the(ir) target product ingredient(s), production or use volumes and product (material) lifecycle properties, the geographic region (EU country) of interest. Collaboration can be protected by a confidential agreement between the user and the service provider.
One key property of this prototype predictive software for risk vulnerability is that it is designed to do its best when encountering scanty and uncertain data (which often happens in environmental and health contexts). This, however, only works when the above-mentioned background database can be established so it provides a large spectrum of data for optimistic-to-worst-case value ranges of model input information. The main outputs (see examples in Fig. 2) distinguish risk (toxicity and exposure), vulnerability (fraction of organisms and creatures potentially harmed) and concentrations (potential contamination load concentrations).
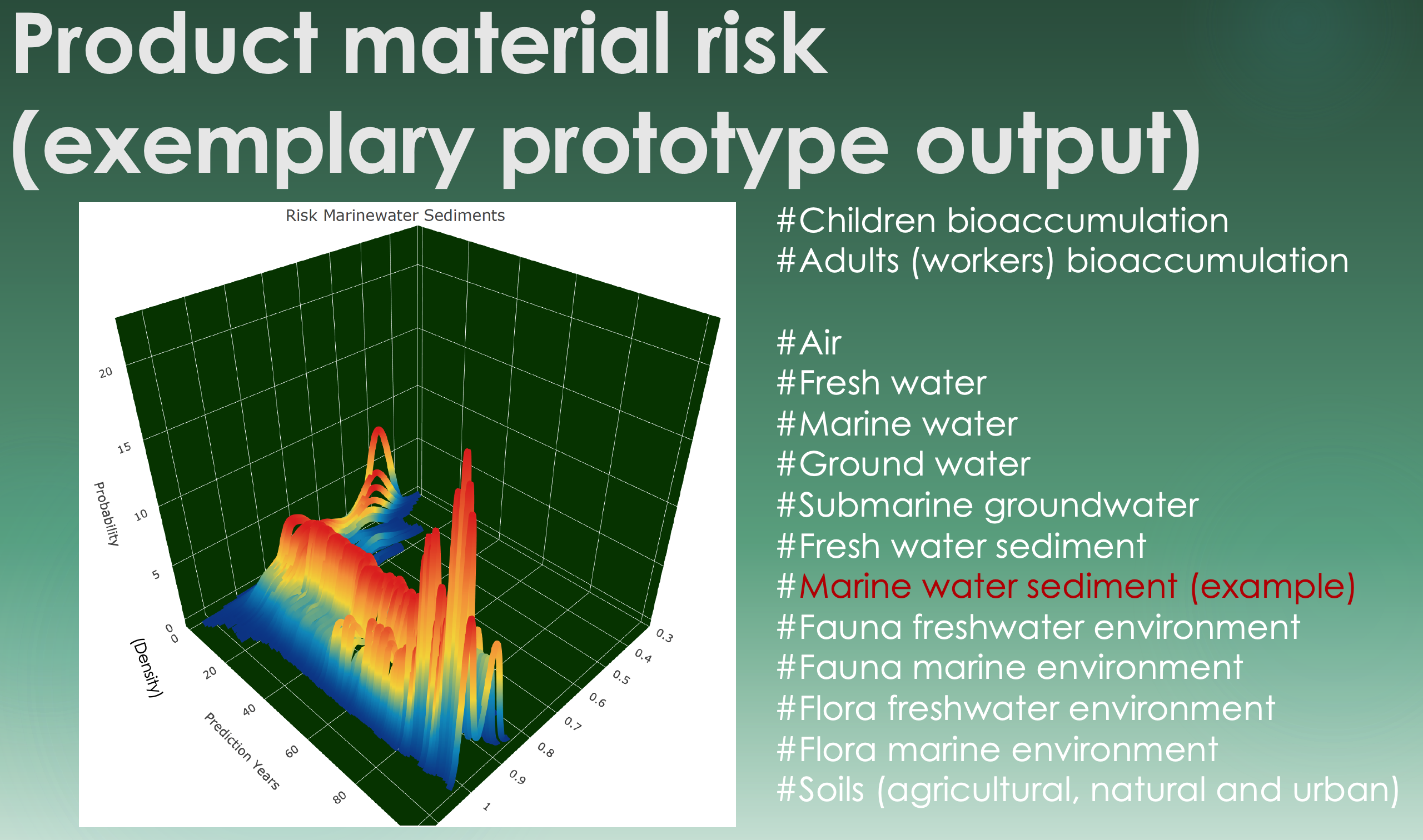
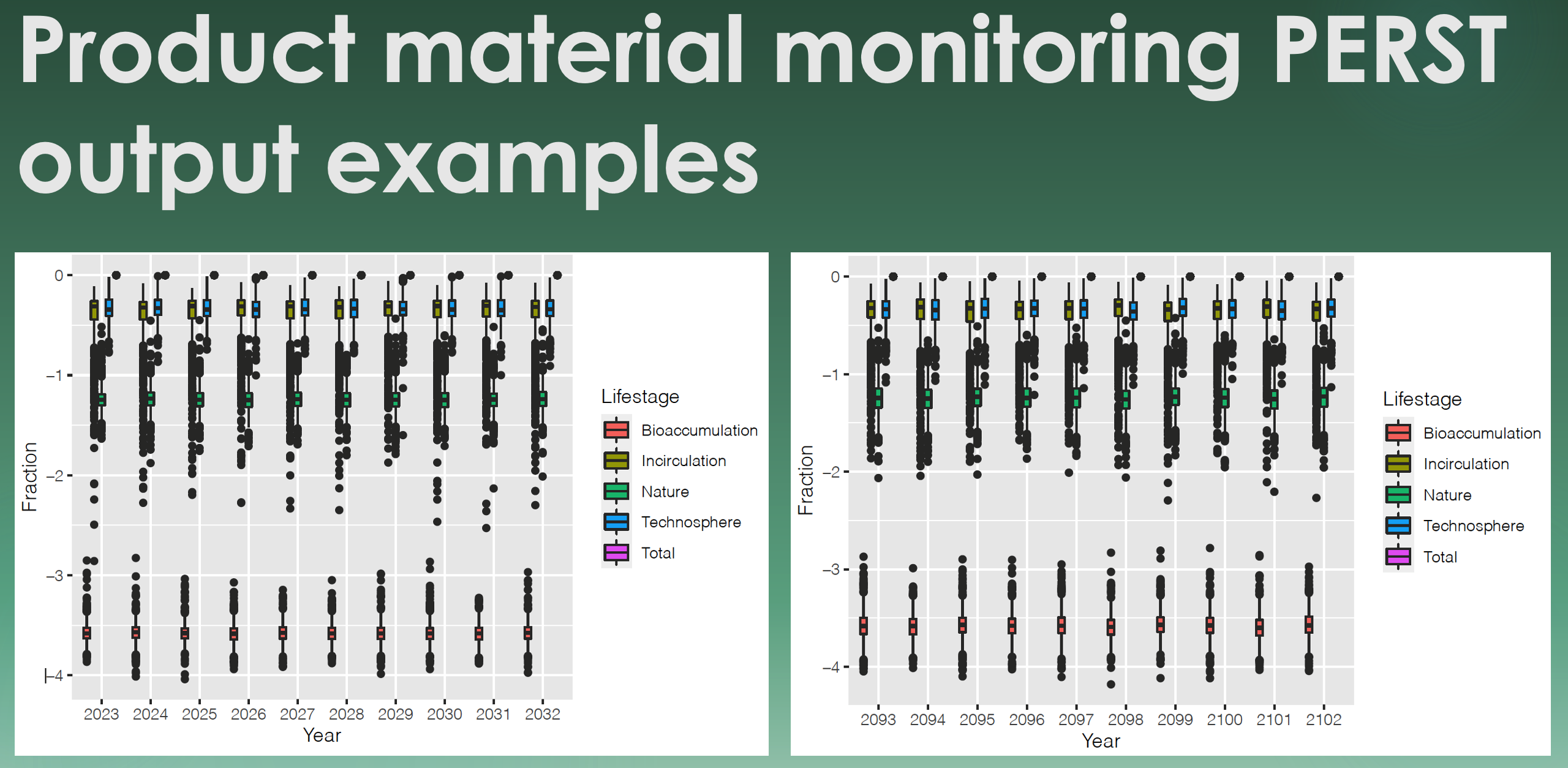
Figure 2: Fundamental PERST output types, such as 3D graphics (probability is used synonymously with density [z-axis]), boxplots summarising these output distributions over time and line charts (not shown here) visualising the evolution of a target variable. The PERST risk etiquette is under construction and is not illustrated here.
PERST runs in two modes: a) a pure target product database mode and b) a so-called PERST expanded mode, where such target product data are partly virtually created by the tool when embedded in broader, beyond-normal product use and material emission dynamics.
Although it is more idealistic in its objectives, the prototype tool methodology freely originates from stochastic-probabilistic material release flow (Gottschalk et al. 2009) and species sensitivity distribution (and risk; Gottschalk et al. 2013) approaches widely used and developed, such as those extensively shown in Giese et al. (2018). At the present prototype stage, however, PERST is newly developed and no longer mass flow-oriented. Instead, it purely builds on probabilistic predictions of the target material’s (product ingredient’s) location and transformation over its lifecycle and beyond. This also works well for long periods (a century or longer), as confirmed by initial tests partially run with synthetic data and assuming the necessary data for running such calculations will be available in the future. Furthermore, in fundamental contrast to the compared references, PERST performs without predefined (theoretical and other) probability distributions but generates them, which also works for the (eco)toxicity parts of predictive modelling. In doing so, the developed programming in R (R Development Core Team 2021) follows fundamental arithmetic operations embedded to different extents into its own Monte Carlo, Bayes and other (combinations thereof) computational learning concepts.
The software is designed to glean as much information as possible from the available data, especially if such data are highly sparse or not embedded in too-robust consistency concerning their scientific knowledge background. This largely protects the predictive tool output from being biased by potentially uncertain or crude expert or product producers‘ opinions, for example on fixed data input parameters or probability distribution forms for those parameters. Furthermore, this considerably reduces the amount of data that must be delivered from the user side and may augment the approached practicability of the tool service. One PERST-prototype computer simulation round takes little more than an hour, and it produces a 242-page PDF document. Such output distinguishes the following: i) 3D graphics of probability results in their time dynamics which are revealed as density plots that provide the distribution of all numeric predictions; ii) boxplots that reveal a summary (range, median and some percentiles) of these output distributions; iii) line charts visualising a time series that reveals the evolution of the target variable, possibly in the future and iv) the PERST risk etiquette for the evaluated product (material). The latter is not yet incorporated into the automatised tool output and has not been defined in its graphical or labelling appearance or in its composition of risk scores to take from PERST. The tool’s performance has successfully been tested in some tool-use attempts, partially based on synthetic data and covering a few products: i) automotive products (carbon nanofibers [CNF]) used in Spain, ii) chemical–mechanical polishing used in Germany (CeO2-ENM), iii) automotive catalytic converters (CeO2-ENM) used in Germany and iv) rubber tires (carbon black [CB]) used in Denmark. These results are only used for prototype software demonstration and testing purposes. A first version of this descriptive summary of PERST is available as PDF document. The exact terms of the planned PERST services for potential clients in industry and other fields have not been determined yet, but will be communicated later.
Partners from the research fields of a) human toxicology, b) ecotox, c) product-material human exposure (release), d) product-material environmental exposure (release) willing to build and research a real or synthetic data background should get in touch with Fadri Gottschalk (+41818601085).
References
Giese, B., F. Klaessig, B. Park, R. Kaegi, M. Steinfeldt, H. Wigger, A. von Gleich, and F. Gottschalk. 2018. Risks, release and concentrations of engineered nanomaterial in the environment. Scientific Reports 8:1565.
Gottschalk, F., E. Kost, and B. Nowack. 2013. Engineered nanomaterials in waters and soils: A risk quantification based on probabilistic exposure and effect modeling. Environmental Toxicology & Chemistry 32:1278–1287.
Gottschalk, F., T. Sonderer, R. W. Scholz, and B. Nowack. 2009. Modeled environmental concentrations of engineered nanomaterials (TiO2, ZnO, Ag, CNT, fullerenes) for different regions. Environmental Science and Technology 43:9216–9222.
R Development Core Team. 2021. R: A language and environment for statistical computing. R version 4.1.2 (2021-11-01)
Project-Team
Fadri Gottschalk*, Michael Steinfeldt**, Bernd Giese***, Sebastian Purker***, Carina R. Lalyer***, Isabel Rodriguez**** et al.
*ETSS AG, Engineering, technical and scientific services, CH-7558, Strada, Switzerland
**University of Bremen, Faculty of Production Engineering, Department of Technology Design and Technology Development, Badgasteiner Str, 1 28359, Bremen, Germany
***University of Natural Resources and Life Sciences, Institute of Safety and Risk Sciences, Borkowskigasse 4, 1190, Vienna, Austria
****GAIKER Technology Centre, Parque Tecnológico, Ed. 202. 48170 Zamudio (Bizkaia) SPAIN
